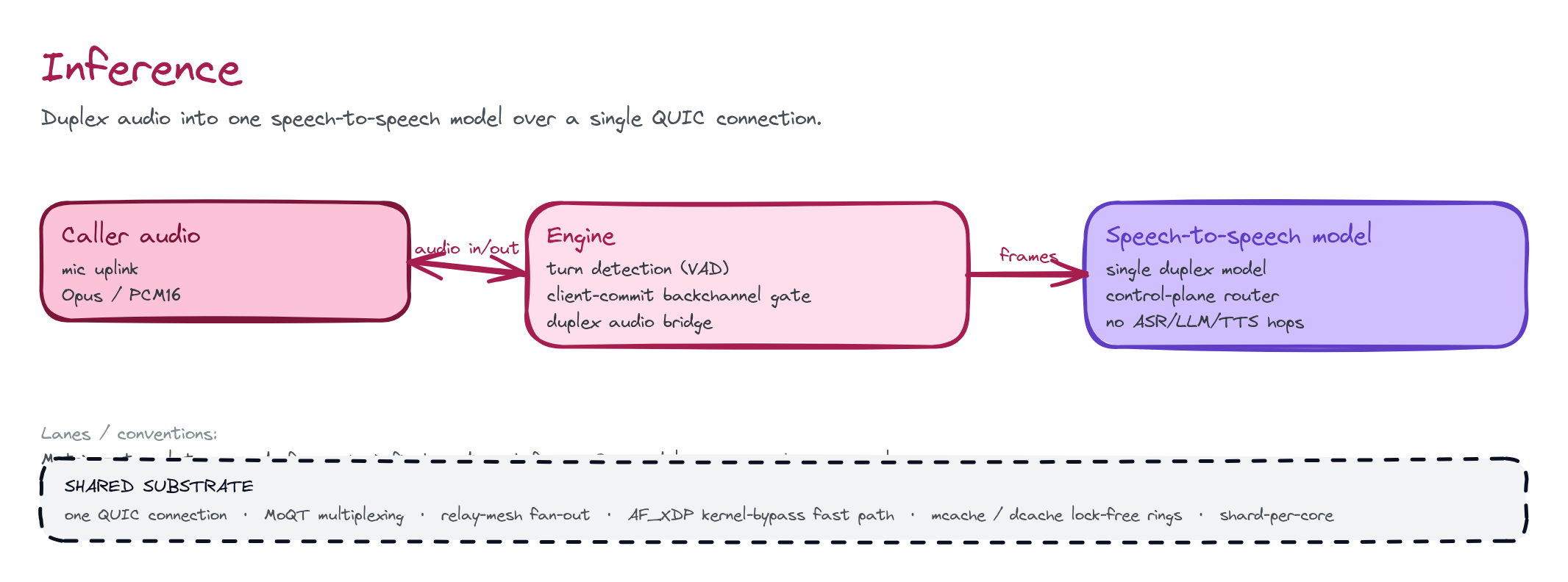
Why one model, not a pipeline
The classic voice-agent stack is a cascade: streaming ASR → an LLM → a TTS voice, three services chained together. ClutchCall supports that path too (see Turn Detection). The inference modality is the single-model alternative: one speech-to-speech model that takes audio in and emits audio out directly, with no transcript hop in the middle.| Cascade (ASR → LLM → TTS) | Speech-to-speech (this modality) | |
|---|---|---|
| Stages on the wire | 3 sequential request/responses | 1 duplex stream |
| Turn-taking owner | gateway VAD or the realtime LLM | the client (commit-driven) |
| First-audio latency | ASR finalize + LLM TTFT + TTS TTFA | model emits audio as it hears you |
| Prosody / tone | lost at the transcript boundary | preserved end-to-end |
The wire model
The model leg reuses the Voice modality’s track convention. A call carries two audio tracks, and the agent attach binds the model to both:There is no “send the whole utterance, then wait” round-trip. Continuous
prefill plus the commit gate (below) is what gives a near-zero gap between
end-of-speech and the first audio-out frame.
Turn-taking: the client-commit gate
A server-side VAD model decides on its own when your turn ended and starts talking. A speech-to-speech model has no server VAD — so the decision of when the user’s turn ended is ClutchCall’s to make, locally. This is a feature, not a gap: it is the protocol-clean place to gate backchannels. ClutchCall runs a local turn detector over the inbound caller audio and drives the model with explicit signals:Append (continuous)
Caller audio frames are appended to the model’s input buffer at 1x
real-time. The model is already “listening” while the caller talks.
Prime (open turn)
A non-final commit keeps a turn primed without asking for a reply yet — the
listening window stays open.
Backchannel suppression
Short continuers — “ok”, “mhm”, “yeah”, “right” — are exactly what you do not want to treat as a turn. The turn detector filters any speech burst shorter thanresponse_min_speech_ms (default 600 ms): it never produces a final commit,
so the model never wakes up to answer it, and the agent keeps its floor.
Barge-in: hold-and-confirm
When the caller speaks over the agent, naive logic cancels the agent on the very first speech frame — so a muttered “mhm” mid-sentence kills the whole reply. ClutchCall instead arms a pending barge-in on speech onset and only fires it once speech has been sustained forbarge_confirm_ms (default 300
ms). A backchannel ends before the window elapses → no cancel, the agent keeps
talking. A real interruption runs past the window → the agent is cancelled,
~barge_confirm_ms later than a naive cut (the only cost).
Codecs
The model wants raw audio; the caller leg may be anything. ClutchCall transcodes at the bridge, so you pick what the model expects and the call leg is handled for you.| Codec | When |
|---|---|
pcm16 | Default for the model leg. Raw 16-bit PCM, what most speech-to-speech models ingest. ClutchCall resamples between the caller rate (commonly 8 kHz on PSTN) and the model’s rate (commonly 16 kHz in, 24 kHz out). |
opus | Browser-native and bandwidth-friendly. Use on the browser caller leg; the bridge decodes to PCM16 for the model. |
g711_ulaw / g711_alaw | PSTN-direct caller legs. Transcoded to PCM16 for the model with no ffmpeg in your path. |
The metric that matters: turn latency
The number a caller actually feels is turn latency:turn latency = end-of-user-speech (last inbound audio frame) → start-of-agent-speech (first outbound audio-out frame)Report p50 / p95 / p99, not just the mean — the tail is the product story. Two properties of this modality drive it down:
- Continuous prefill. Because the model hears the utterance as it streams, the final commit only has to flush the tail — first audio out can land within tens of milliseconds of end-of-speech.
- QUIC under load and loss. Over a WAN-emulated link (50 ms RTT, ~1% loss), steady-state QUIC first-token latency is roughly half of TCP+TLS, with a much cleaner p99 tail — no head-of-line blocking when a packet drops mid-turn.
Architecture
The serving path is the same substrate as every other modality, tuned for the inference workload:- One QUIC connection, multiplexed. Uplink and downlink audio plus control signals (commit / cancel) ride independent MoQT streams — a lost packet on one doesn’t stall the others.
- A QUIC front at the edge. A tuned QUIC ingress terminates the caller’s connection and forwards to the model-serving fabric, keeping the model’s routing brain (cache-aware / prefix-aware worker selection) untouched behind it. 0-RTT resumption keeps reconnect churn cheap for edge clients.
- Shard-per-core data plane. The audio fast path runs an AF_XDP kernel-bypass NIC path with lock-free mcache / dcache rings on a thread-per-core reactor and io_uring, so per-turn transport overhead stays in the low single-digit milliseconds even at hundreds of concurrent turns.
When to use it
Use inference when
You want a single speech-to-speech model in the loop, lowest possible
turn latency, prosody preserved end-to-end, and ClutchCall to own
turn-taking and barge-in.
Use the cascade when
You need a specific ASR vendor, a text LLM with tools/RAG, or a particular
TTS voice — the Turn Detection path chains
ASR → LLM → TTS with the same barge-in policy.
Related
- Voice — Details — the call control + audio bridge this modality rides on
- Turn Detection & Barge-In — VAD modes, the cascade path, and the per-vendor support matrix
- Inference — SDK Methods — attaching an agent and the turn-detection knobs